Data Pipeline Automation: weniger Fehler, schnellere Reports

Wenn Zahlen aus dem Online-Shop nicht zusammenpassen, trifft das fast nie „nur“ das Reporting. Meist hängen daran Kampagnenbudgets, Nachbestellungen, Preisentscheidungen und sogar die Verfügbarkeit im Checkout. Und trotzdem laufen Datenflüsse in vielen Shops noch manuell: CSV-Exporte, Copy/Paste in Tabellen, einmal täglich ein Script „auf dem Laptop“, oder ein Connector, der still und leise ausfällt.
Interessiert an diesem Thema?
Kontaktieren Sie uns für eine kostenlose Beratung →Das Ergebnis ist bekannt: Reports kommen zu spät, KPI-Definitionen driften auseinander („Umsatz“ ist plötzlich nicht mehr „Umsatz“), und Teams verlieren Zeit mit Datenreparatur statt mit Optimierung.
Warum Datenpipelines in Online-Shops so oft brechen
Data Pipeline Automation scheitert selten an einem einzelnen Tool. Es sind typische Architektur- und Prozessmuster, die im Alltag unbemerkt zu Risiko werden:
- Uneinheitliche Quellen: Shop-System, Payment, ERP, Versand, Marketing-Ads und Support haben unterschiedliche IDs, Zeitstempel und Datenmodelle. Ohne klare Zuordnung entsteht „Datennebel“.
- API- und Connector-Grenzen: Rate Limits, Pagination, inkonsistente Webhooks oder geänderte API-Felder führen zu stillen Datenlücken. Business-Seite merkt es erst, wenn KPIs kippen.
- Fehlende Datenqualitätsschranken: Wenn niemand prüft, ob z. B. Bestellstatus-Transitions logisch sind (paid → fulfilled → refunded), rutschen falsche Datensätze ins Warehouse.
- Kein belastbares Änderungsmanagement: Ein neues Checkout-Feld, ein ERP-Update oder zusätzliche Versanddienstleister ändern Datenstrukturen – die Pipeline bleibt aber „wie gestern“.
- Zu wenig Observability: Ohne Monitoring, SLAs und Alerting merkt ihr Ausfälle erst über Bauchgefühl oder wenn das Management fragt.
Der betriebswirtschaftliche Effekt ist konkret: Budgets werden auf Basis veralteter oder fehlerhafter Daten verteilt, Lager und Einkauf reagieren zu spät, und Teams bauen Workarounds, die später teuer zurückgebaut werden müssen.
Wie professionelle Data Pipeline Automation im Shop-Kontext aussieht
In der Praxis geht es nicht darum, „alles zu automatisieren“. Es geht darum, kritische Datenpfade so zu bauen, dass sie nachvollziehbar, testbar und erweiterbar sind. Ein bewährter Ansatz lässt sich in drei Ebenen strukturieren:
1) Datenfluss sauber definieren (Business-Logik vor Tool-Auswahl)
Bevor Tools diskutiert werden, wird festgelegt:
- Welche KPIs sind entscheidungsrelevant? (z. B. Deckungsbeitrag, ROAS/POAS, Lieferzeit, Retourenquote)
- Welche Events/Objekte sind „Source of Truth“? (Order, Payment Capture, Refund, Shipment, Return)
- Welche Granularität wird gebraucht? Tagesaggregat vs. Event-Level für Attribution, Forecasting oder Fraud-Checks
- Welche Latenz ist notwendig? Echtzeit, stündlich, täglich – je Use Case unterschiedlich
2) Technische Umsetzung: robust statt „läuft irgendwie“
Typische, praxistaugliche Bausteine sind:
- Ingestion: API Pull, Webhooks, CDC (Change Data Capture) oder Datei-Imports – mit klarer Retry- und Backfill-Strategie.
- Staging + Standardisierung: Rohdaten unverändert speichern (Auditierbarkeit), dann Normalisierung (Zeitzonen, Währungen, IDs).
- Transformation: ELT/ETL mit versionierten Modellen, Tests und dokumentierten KPI-Definitionen.
- Orchestrierung: Zeitpläne, Abhängigkeiten, parallele Jobs, idempotente Läufe.
- Monitoring: Freshness, Volumen-Anomalien, Schema-Drift, Business-Regeln (z. B. „paid ohne order_id“).
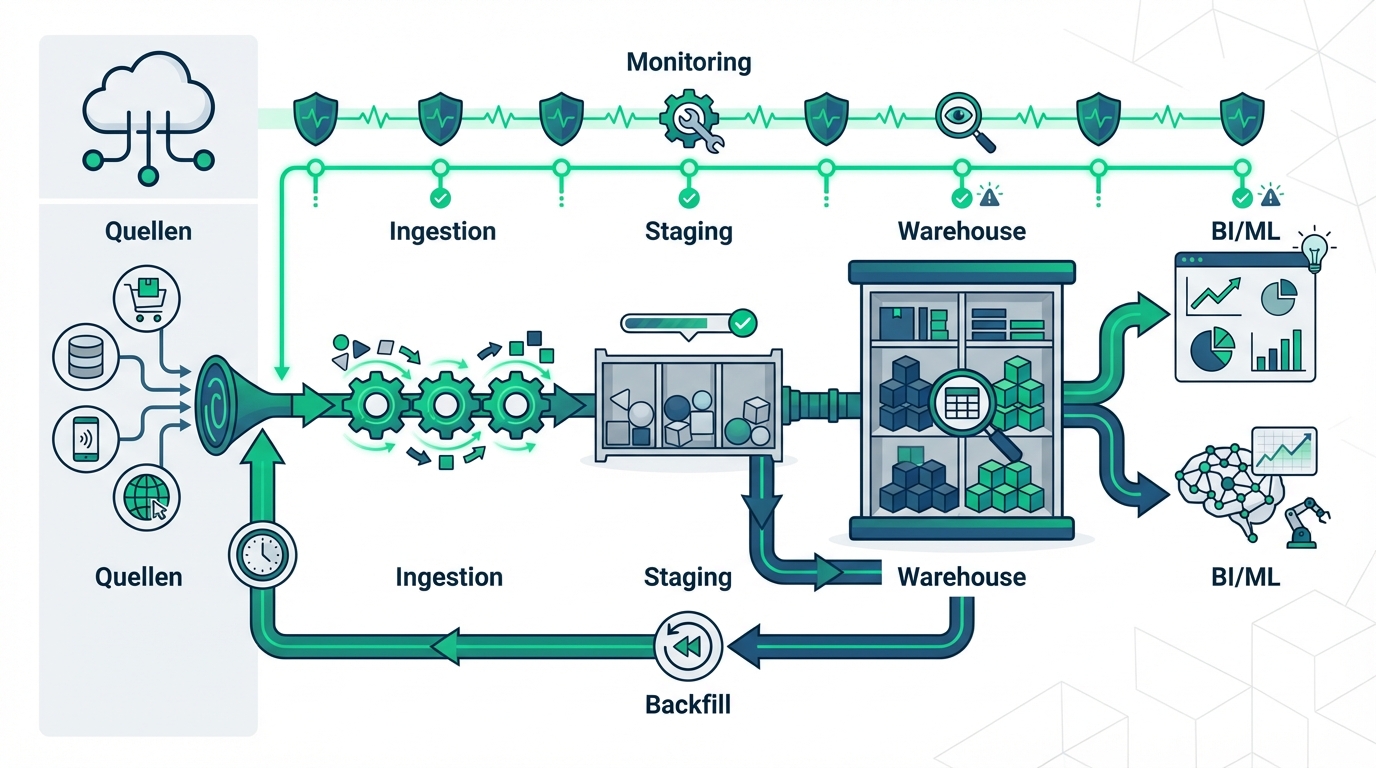
3) Betrieb: Datenprodukte statt Einmal-Projekt
Automatisierte Pipelines sind ein laufendes System. Professionelle Setups etablieren deshalb:
- Ownership: Wer ist verantwortlich für Datenmodelle, Alerts, KPI-Änderungen?
- SLAs: z. B. „Umsatzreport bis 08:30 Uhr“, „Attributionsdaten max. 2 Stunden Verzögerung“.
- Release-Prozess: Änderungen an Tracking, ERP oder Shop-Logik werden vorab auf Datenimpact geprüft.
- Dokumentation: KPI-Definitionen und Datenherkunft, damit Teams nicht „interpretieren“ müssen.
Welche Use Cases im Online-Shop am meisten profitieren
Data Pipeline Automation zahlt sich besonders dort aus, wo Entscheidungen schnell und wiederholbar sind:
- Marketing-Attribution & Budgetsteuerung: konsistente Conversions, saubere Kosten-/Umsatz-Join-Logik, weniger „Blinde Spots“.
- Bestands- und Nachbestelllogik: verlässliche Abverkaufsdaten, Lieferzeiten, Retouren, Forecasts.
- Customer Analytics: Cohorts, CLV, Repeat-Rate, Segmentierung ohne manuelles Matching.
- Pricing & Promotion: messbare Promotion-Effekte, Margen-Sicht, Auswertung nach Kanal und Kategorie.
Woran Du erkennst, dass Automatisierung jetzt sinnvoll ist
- Reports brauchen regelmäßig manuelle „Korrektur“ oder Diskussionen über die richtige Zahl.
- Ein Tool-Wechsel (Shop/ERP/Payment) wirkt wie ein Risiko für das gesamte Reporting.
- Performance-Marketing skaliert, aber Daten kommen zeitverzögert oder unvollständig.
- Mehr als eine Person weiß, „welcher Export der richtige“ ist.

Wenn Dir davon etwas bekannt vorkommt, bringt eine kurze technische Durchsicht der Datenflüsse meistens schnell Klarheit darüber, wo die größten Hebel und Risiken liegen.
Wie Cloudox typischerweise vorgeht
In Online-Shops ist die beste Pipeline die, die langfristig wartbar bleibt. Deshalb starten wir selten mit „Tool X“, sondern mit dem belastbaren Datenmodell und den operativen Anforderungen (Latenz, SLA, Governance). Je nach Bestandssystemen integrieren wir passende Bausteine für Ingestion, Orchestrierung, Transformation und Monitoring und sorgen dafür, dass KPI-Definitionen versioniert und testbar sind.
Wenn Du neben Reporting auch Use Cases wie Forecasting, Next-Best-Offer oder Prozessautomatisierung auf Datenbasis planst, ist der nächste sinnvolle Schritt oft eine fachliche und technische Einordnung über unsere KI Agentur.
Was Du vor dem Start intern klären solltest
- KPI-Owner: Wer entscheidet final über Definitionen (z. B. „Umsatz netto“, „storniert“, „retourniert“)?
- Systemlandschaft: Welche Quellen sind kritisch (Shop, ERP, Payment, 3PL, Ads)?
- Datenzugänge: API-Scopes, Webhook-Rechte, DB-Read-Access, Export-Routinen.
- Compliance: DSGVO, Aufbewahrung, Pseudonymisierung/Hashing, Zugriffskonzepte.
- Erwartete Latenz: Welche Entscheidungen brauchen welche Aktualität?


