Machine Learning Beratung: weniger Retouren, mehr Marge

Wenn Daten da sind, aber Entscheidungen trotzdem „nach Gefühl“ passieren
Viele Online-Shops haben heute genug Daten: Bestellungen, Klicks, Retouren, Marketingkosten, Lagerbewegungen. Trotzdem bleibt das Tagesgeschäft oft überraschend manuell: Forecasts in Excel, Regeln für Produktempfehlungen, händische Betrugsprüfungen, Kundenservice-Triage nach Bauchgefühl. Das Ergebnis sind Streuverluste (z. B. zu breite Kampagnen), operative Reibung (zu viele Tickets, zu viele Ausnahmen) und am Ende häufig ein Problem, das jeder kennt: Marge geht verloren, ohne dass ein einzelner „großer Fehler“ sichtbar wäre.
Interessiert an diesem Thema?
Kontaktieren Sie uns für eine kostenlose Beratung →Warum das passiert: Daten sind vorhanden, aber nicht ML-tauglich
Machine Learning scheitert im Commerce selten an der Idee – sondern an der Umsetzbarkeit. Typische Ursachen sind:
- Uneinheitliche Datenlogik: Produkt-IDs, Varianten, Bundles, Stornos, Teillieferungen – im Tracking anders abgebildet als im ERP. Modelle lernen dann „falsche Wahrheiten“.
- Zu viele Zielkonflikte: Umsatz maximieren vs. Retouren senken vs. Lager drehen. Wenn das Optimierungsziel nicht sauber definiert ist, wird ML zur Blackbox ohne Business-Akzeptanz.
- Keine saubere Feedback-Schleife: Empfehlungen laufen, aber niemand misst inkrementellen Uplift (z. B. gegen Kontrollgruppen). Dann ist unklar, ob ML wirkt oder nur Korrelationen ausnutzt.
- Produktionsbetrieb fehlt: Ein Notebook-Prototyp ist nicht das Gleiche wie ein robustes System mit Monitoring, Drift-Erkennung, Rollbacks und klaren SLAs.
Die businessseitige Folge: Entscheidungen werden wieder auf Regeln zurückgestellt, weil Vertrauen und Stabilität fehlen – und das Team bleibt im operativen Feuerlöschen.
Wie professionelle Machine Learning Beratung im Online-Shop typischerweise vorgeht
Gute Beratung ist weniger „Modell bauen“ und mehr Systemdesign + Priorisierung. Ein bewährter Ablauf sieht so aus:
1) Use-Cases auswählen, die wirklich wirtschaftlich sind
Statt mit „Wir brauchen KI“ zu starten, beginnt man mit den größten Hebeln entlang der Wertschöpfung. Häufige ML-Use-Cases im Shop-Kontext:
- Demand Forecasting (bessere Disposition, weniger Stockouts/Überbestände)
- Return Prediction (Risikoprodukte/Größen, präzisere Size-Guides, bessere QC-Checks)
- Churn & CLV (gezieltere CRM-Automation statt Rabatt-Gießkanne)
- Recommendation & Search Ranking (mehr Relevanz, weniger „Nulltreffer“)
- Fraud/Payment Risk Scoring (weniger Chargebacks, weniger manuelle Reviews)
Wichtig ist: Jeder Use-Case bekommt ein messbares Ziel (z. B. „Retourenquote um X% relativ senken“ oder „Forecast-Fehler MAPE um Y verbessern“) und eine klare Messlogik.
2) Datenbasis und Events so aufbauen, dass ein Modell nicht „halluziniert“
Im Commerce ist Feature-Qualität oft der Engpass. Dazu gehört typischerweise:
- Definition einer kanonischen Produkt-/Variantensicht (PIM/Shop/ERP konsistent)
- Session- und Event-Tracking mit sauberen IDs (User, Device, Consent-konform)
- Labeling-Logik: Was zählt als Retoure? Welche Zeitfenster? Wie werden Teillieferungen behandelt?
- Data Quality Checks (z. B. Ausreißer, Missing Values, Duplikate)
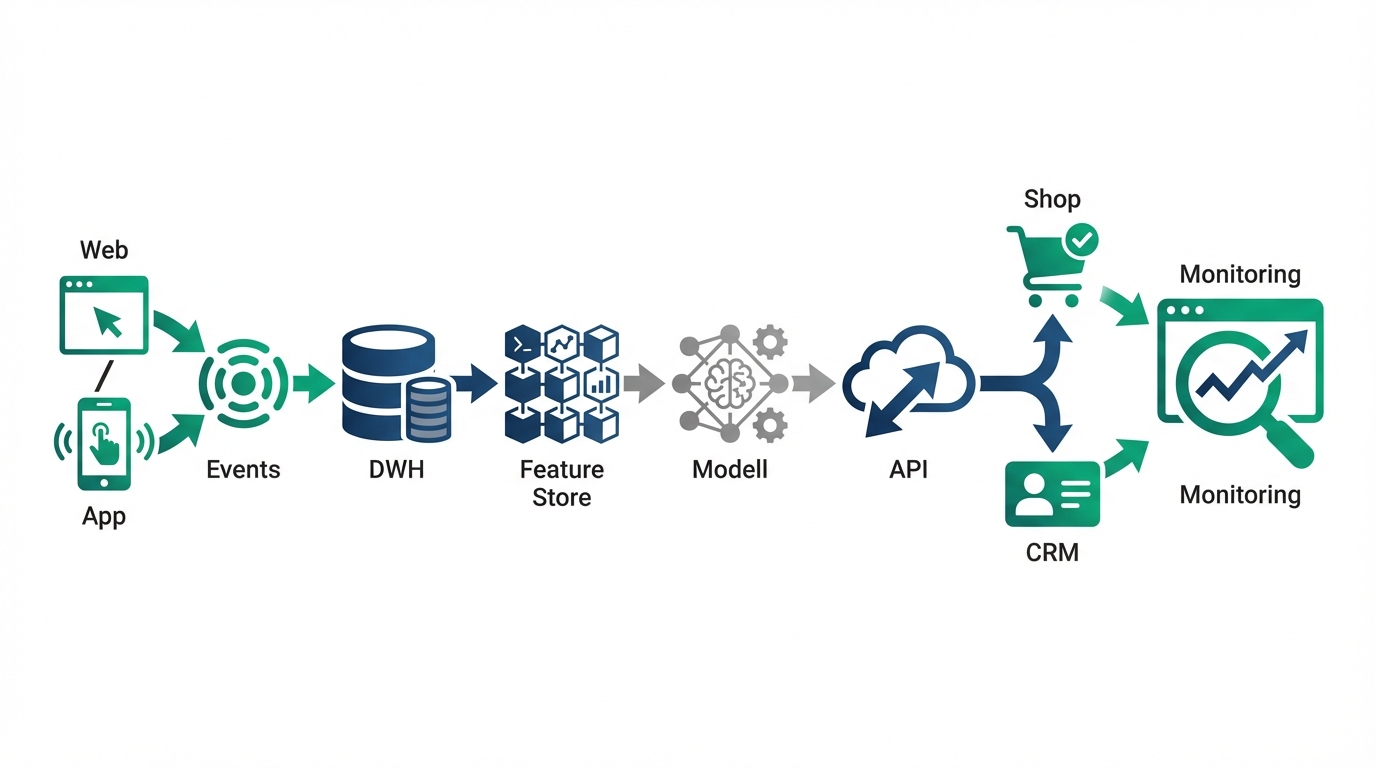
3) Modellierung pragmatisch: erst baseline, dann „smart“
In der Praxis gewinnt oft ein solides Baseline-Modell (z. B. Gradient Boosting für tabellarische Daten) gegen überambitionierte Ansätze, wenn Datenlage und Betrieb noch nicht reif sind. Beratung bedeutet hier, die passende Komplexität zu wählen:
- Baseline: schnell validierbar, stabil, gut erklärbar
- Inkremente: Feature Engineering, Kalibrierung, Segmentmodelle
- Erst später: Deep Learning/Sequence Models, wenn Events/Skalierung es hergeben
4) Messen wie ein Produktteam: Uplift statt „Accuracy“
Eine der häufigsten Enttäuschungen entsteht, wenn ein Modell „90% genau“ ist, aber keinen Euro bringt. Im Shop zählen deshalb:
- Inkrementeller Uplift (A/B-Test oder Holdout)
- Business-KPIs (Marge, Retourenkosten, Lagerreichweite, Support-Minuten)
- Fairness & Risiko (z. B. Fraud-Blocking nicht zu aggressiv, sonst False Positives)
Wenn Dir einige Punkte bekannt vorkommen: Eine kurze technische Review klärt meist schnell, ob der Engpass eher Daten, Tracking, Modellierung oder Betrieb ist.
5) Betrieb (MLOps): Stabilität, Monitoring, Verantwortlichkeiten
Damit ML im Tagesgeschäft nicht „ausfällt“, wird es wie ein Produkt betrieben: Versionierung, CI/CD, Observability, Drift-Checks, sowie klare Zuständigkeiten (wer reagiert bei KPI-Abfall?). Typisch sind:
- Model Monitoring (Input-Drift, Output-Drift, KPI-Drift)
- Retraining-Strategie (zeitbasiert oder ereignisbasiert)
- Rollout-Strategie (Canary, Feature Flags, schnelle Rollbacks)

Woran Du gute Machine Learning Beratung erkennst (ohne Buzzwords)
- Sie startet mit Messbarkeit: Ziel, Baseline, Testdesign, Erfolgskriterium.
- Sie spricht über Datenverträge: Welche Felder, welche Definitionen, welche Aktualität.
- Sie plant Integration: Wie kommt ein Score in Shop/CRM/ERP? Welche Latenz ist akzeptabel?
- Sie adressiert Risiko: Datenschutz, Bias, False Positives, Support-Fallbacks.
- Sie macht Betrieb konkret: Monitoring, Ownership, Incident-Prozess.
Wie Cloudox dabei typischerweise unterstützt
Wenn Du ML im Online-Shop nicht als Experiment, sondern als verlässlichen Wachstumskanal aufsetzen willst, ist der nächste sinnvolle Schritt meist eine strukturierte Bestandsaufnahme (Daten, Ziele, Integrationspunkte, Risiken) und daraus ein umsetzbarer Fahrplan. Genau dafür ist unsere KI Agentur gedacht – mit Fokus auf Commerce-Use-Cases, saubere Messmethoden und robuste Produktionsumsetzung.
Nächster Schritt (ohne Verkaufsdruck)
Wenn Du magst, schauen wir uns gemeinsam an, welche 1–2 Use-Cases in Deinem Shop den schnellsten, messbaren Effekt haben – und welche Voraussetzungen dafür wirklich fehlen (oft weniger, als man denkt).


