Magento 2 Architektur optimieren: Blueprint für Entwickler & Architects (Varnish, Redis, GraphQL, PWA, Cloud)

1) Architektur-Analyse: Engpässe in Magento 2 systematisch finden
Request-Flow in Schichten prüfen (Edge → Cache → App → DB)
Optimierungen funktionieren nachhaltig nur, wenn du den Request-Flow als Kette betrachtest: CDN/Edge (optional) → Varnish → Magento (PHP-FPM) → Services (Redis, Elasticsearch/OpenSearch) → MySQL. Ziel: maximale Cache-Hit-Rate, stabile Latenzen unter Last und kontrollierte Degradierung bei Teil-Ausfällen.
Interessiert an diesem Thema?
Kontaktieren Sie uns für eine kostenlose Beratung →Praktische Checks (Architecture Health):
- Cache-Strategie: Full Page Cache (Varnish) korrekt? Cache-Invalidation sauber? TTL & Grace passend?
- Session/Cache-Backend: Redis getrennt für Sessions/Cache? Eviction-Policy passend?
- API-Schicht: REST vs GraphQL (für Headless/PWA Studio) – Query-Cost & Caching?
- Cloud/Infra: In Adobe Commerce Cloud Skalierung/Autoscaling, Service-Container Sizing, Deploy-Pipeline, Warmup.
- Datenbank: Slow Queries, fehlende Indexe, Locking/Deadlocks, InnoDB Buffer Pool, Replica-Read-Strategien.
flowchart LR U[User / Bot] --> CDN[CDN/Edge] CDN --> V[Varnish FPC] V -->|HIT| U V -->|MISS| PHP[Magento PHP-FPM] PHP --> R1[Redis Cache] PHP --> R2[Redis Sessions] PHP --> ES[Elasticsearch/OpenSearch] PHP --> DB[(MySQL/InnoDB)] PHP --> V PHP --> OBS[Observability: APM/Logs/Traces]
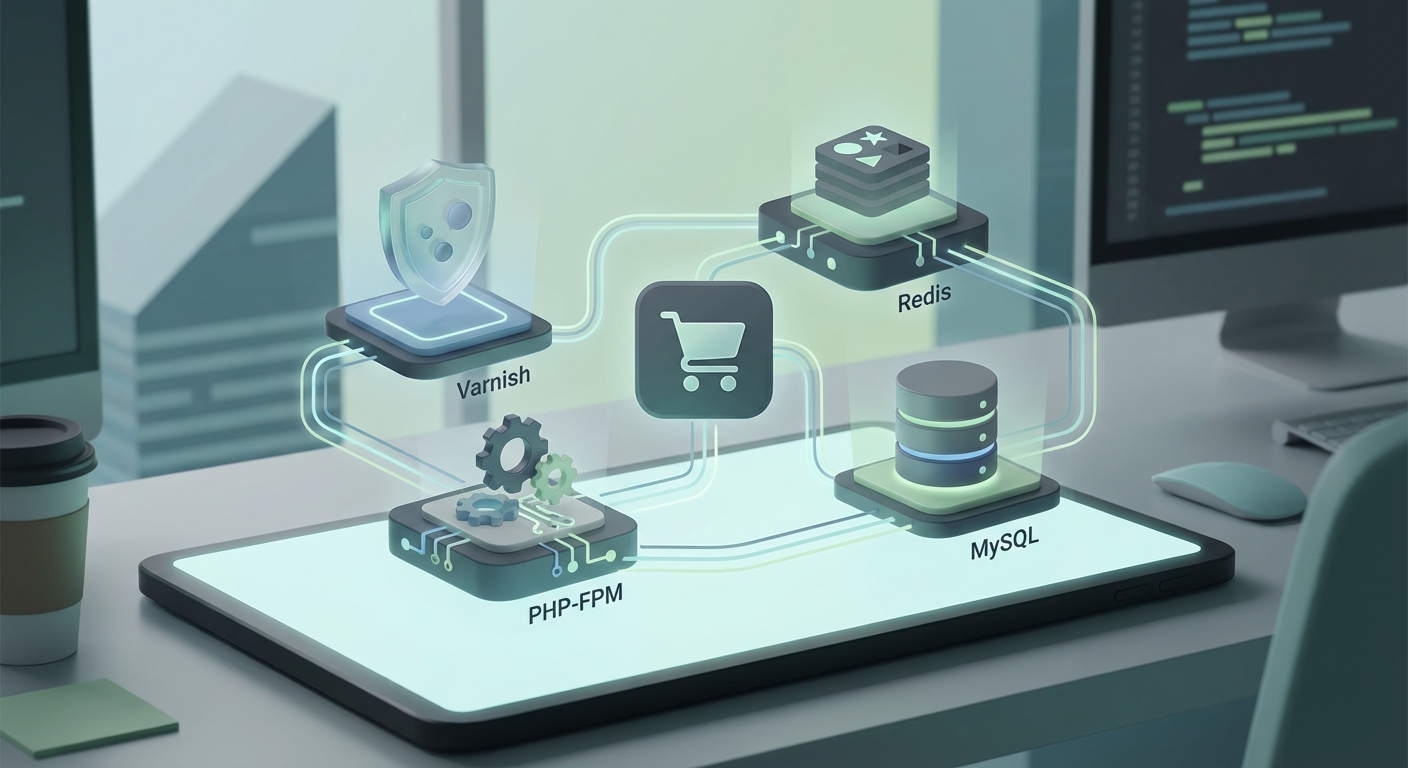
2) Varnish Full-Page-Cache optimieren (inkl. Varnish Grace Mode)
Warum Varnish Grace Mode architektonisch entscheidend ist
Varnish Grace Mode erlaubt, abgelaufene Cache-Objekte für eine definierte Zeit weiterhin auszuliefern, wenn das Backend (Magento) langsam ist oder Fehler liefert. Damit erreichst du „stale-while-revalidate“-ähnliches Verhalten: Nutzer bekommen schnell eine (leicht veraltete) Seite, während Varnish im Hintergrund neu validiert. Das reduziert Error-Spikes bei Deploys, DB-Spitzenlast oder PHP-FPM-Sättigung.
Effekt:
- Schützt die Applikation vor Traffic-Spitzen nach Cache-Expiry.
- Stabilisiert Conversion-relevante Seiten (Kategorie, PDP) auch bei Backend-Degradation.
- Verbessert TTFB massiv bei incident-nahen Szenarien.
Konkrete Tuning-Ansätze
- Grace sinnvoll dimensionieren: z. B. 2–10 Minuten für Kategorieseiten, länger für CMS, kürzer für Preis-/Stock-sensitive Inhalte (abhängig von Setup).
- Backend Health Checks: Grace nur aggressiv nutzen, wenn Backend als unhealthy/slow gilt.
- Ban/Invalidation-Strategie: Tags & Purges sauber halten, damit Grace nicht „falsches“ stale ausliefert.
VCL-Beispiel (Grace/Backend Handling)
Hinweis: Details variieren je nach Magento-Version/VCL-Basis. Ziel ist zu zeigen, wo Grace/Keep typischerweise gesetzt werden.
Varnish VCL: Grace & Keep konfigurieren
```yaml # Beispielhaft als VCL-Snippet in YAML eingebettet (z.B. für IaC/Config-Management) varnish: vcl_snippets: - name: default_grace content: | sub vcl_backend_response { # Standard: Objekt darf nach TTL noch X Sekunden "stale" sein set beresp.grace = 5m; # Keep ermöglicht Revalidation ohne sofortiges Evict set beresp.keep = 10m; } sub vcl_hit { if (obj.ttl <= 0s) { # Wenn abgelaufen, aber innerhalb Grace, liefern wir stale aus if (obj.grace > 0s) { return (deliver); } } } ```3) Redis richtig betreiben (inkl. Redis Eviction): Cache- und Session-Architektur
Trennung von Redis-Workloads
Architektonisch bewährt: mindestens zwei Redis-Instanzen bzw. zwei logisch getrennte DBs/Cluster – eine für Sessions (kritisch) und eine für Cache (FPC/Config/Default). So vermeidest du, dass Cache-Spitzen Session-Daten verdrängen.
Redis Eviction: Was es ist und wie du Datenverlust vermeidest
Redis Eviction bezeichnet das Verdrängen von Keys, sobald maxmemory erreicht ist. Das ist bei Cache gewünscht (kontrolliert), bei Sessions meist fatal (Logout, Warenkorbverlust).
Empfehlungen:
- Sessions:
maxmemory-policy noeviction(oder sehr konservativ mit separatem Cluster). Wenn Memory voll: lieber Alarm + Skalierung statt stiller Datenverlust. - Cache:
allkeys-lfuodervolatile-lruje nach TTL-Strategie; LFU ist oft stabil unter wechselnden Traffic-Mustern. - Monitoring: Evicted keys, hit rate, latency, memory fragmentation, replication lag (falls repliziert).
| Feature | Details |
|---|---|
| Redis Sessions | Separater Redis/DB, Policy: noeviction, Alarm bei Memory-Schwelle, Persistenz nach Bedarf |
| Redis Cache | Policy: allkeys-lfu oder volatile-lru, TTL konsequent setzen, Hit-Rate als KPI |
| Varnish Grace Mode | Liefert stale Content bei Backend-Problemen, reduziert Error-Spikes & schützt PHP/DB |
| GraphQL Layer | Persisted Queries + CDN/Varnish Cache, Query-Cost-Limits gegen teure Abfragen |
| Adobe Commerce Cloud | Automatisierte Deployments, Service-Tuning (Redis/ES), Blue-Green/Zero-Downtime-Strategien |
4) Headless & API: GraphQL für PWA Studio performant machen
GraphQL-Performance-Hebel
- Persisted Queries: reduziert Payload, stabilisiert Caching und verhindert „Ad-hoc“ Monster-Queries.
- Query Complexity/Depth Limits: verhindert DoS über GraphQL.
- Cache-Strategie: CDN/Varnish für GET-basierte persisted Queries; serverseitig Resolver-Cache, wo sinnvoll.
- PWA Studio: Build/SSR-Strategie prüfen, API-Aggregation minimieren, kritische Queries priorisieren (above the fold).
JSON Config für API Endpoints
```json { "api": { "baseUrl": "https://www.example.com", "graphqlEndpoint": "/graphql", "rest": { "integrationTokenEndpoint": "/rest/V1/integration/admin/token", "healthEndpoint": "/rest/V1/cmsPageIdentifier/health" }, "graphql": { "persistedQueries": { "enabled": true, "allowListUrl": "https://cdn.example.com/graphql/allowlist.json", "defaultCacheTtlSeconds": 120 }, "limits": { "maxDepth": 10, "maxComplexity": 3000 } } } } ```TypeScript: Persisted Query Client (PWA Studio/Node Layer)
Beispiel für einen Client, der operationName + variables zu einem Hash mappt (Persisted Queries), um Cachebarkeit zu erhöhen.
TypeScript Beispiel: Persisted GraphQL Fetch
```typescript type PersistedQueryRequest = { operationName: string; variables?: Record5) Adobe Commerce Cloud: Deploy- und Runtime-Architektur auf Stabilität trimmen
Wichtige Cloud-Patterns
- Zero/Low-Downtime Deploy: Wartungsfenster minimieren, Warmup nach Deploy (Top-URLs, GraphQL persisted queries).
- Service Sizing: Redis/Elasticsearch RAM/CPU an realen Peak ausrichten; getrennte Redis-Rollen.
- Readiness/Health: harte Checks für App/DB/Redis, damit Autoscaling nicht „kaputte“ Nodes hochzieht.
- Observability: Apdex, Cache hit ratio, Redis evictions, DB slow queries, PHP-FPM saturation.
YAML: Beispiel für Cache-Warmup Job nach Deployment
```yaml name: cache-warmup on: workflow_dispatch: push: branches: [ "main" ] jobs: warmup: runs-on: ubuntu-latest steps: - name: Warm category + product pages env: BASE_URL: https://www.example.com run: | set -e URLS=( "/" "/men.html" "/women.html" "/checkout/cart" ) for u in "${URLS[@]}"; do echo "Warming $u" curl -sS -o /dev/null -D - "$BASE_URL$u" \ -H 'Cache-Control: no-cache' \ -H 'User-Agent: warmup-bot/1.0' done ```6) Python: Caching-Optimierung messen & automatisiert verbessern
Das folgende Script prüft exemplarisch Response-Header (z. B. X-Cache, Age) und erzeugt eine kleine Auswertung. Damit kannst du nach Deploys oder Config-Änderungen (Varnish/TTL/Grace) schnell sehen, ob die Cache-Hit-Rate für kritische URLs steigt.
Python Script for Caching Optimization
```python import time import csv import requests from urllib.parse import urljoin BASE_URL = "https://www.example.com" URLS = [ "/", "/men.html", "/women.html", "/customer/account/login/", ] HEADERS = { "User-Agent": "cache-audit/1.0", "Accept": "text/html,application/xhtml+xml", } def fetch(url: str): t0 = time.perf_counter() r = requests.get(url, headers=HEADERS, timeout=20) dt_ms = (time.perf_counter() - t0) * 1000 # Common varnish headers differ by setup; adjust for your environment x_cache = r.headers.get("X-Cache", "") age = r.headers.get("Age", "") cache_control = r.headers.get("Cache-Control", "") return { "url": url, "status": r.status_code, "ttfb_ms": round(dt_ms, 2), "x_cache": x_cache, "age": age, "cache_control": cache_control, } def audit(iterations: int = 2, sleep_s: float = 0.2): results = [] for i in range(iterations): for path in URLS: full = urljoin(BASE_URL, path) results.append(fetch(full)) time.sleep(sleep_s) return results def summarize(rows): hits = 0 total = 0 for r in rows: total += 1 # naive heuristic: many setups return "HIT"/"MISS" in X-Cache if "HIT" in (r["x_cache"] or ""): hits += 1 hit_rate = (hits / total) * 100 if total else 0 return {"total": total, "hits": hits, "hit_rate_percent": round(hit_rate, 2)} if __name__ == "__main__": rows = audit(iterations=3) summary = summarize(rows) print("Summary:", summary) with open("cache_audit.csv", "w", newline="", encoding="utf-8") as f: w = csv.DictWriter(f, fieldnames=list(rows[0].keys())) w.writeheader() w.writerows(rows) # Actionable suggestion based on outcome if summary["hit_rate_percent"] < 70: print("Hint: Consider reviewing Varnish TTL/Grace, cache tags invalidation, and cookies that bypass cache.") ```7) Architektur-Checkliste: Die wichtigsten Optimierungen (Pillar)
- Varnish: Grace/Keep korrekt, Backend-Health-Handling, Cache-Warmup, Cookie-Bereinigung.
- Redis: getrennte Instanzen/DBs, Sessions = noeviction, Cache = LFU/LRU, Eviction-Metriken alarmieren.
- GraphQL/PWA Studio: persisted queries, complexity limits, GET-cacheability, Resolver-Optimierung.
- Adobe Commerce Cloud: service sizing, Deploy-Warmup, Observability-first, Runbooks.
- Datenbank: slow query log, Index-Hygiene, Locking-Analyse, richtige Transaction-Isolation.
Wenn du diese Punkte als belastbares Zielbild (Target Architecture) aufsetzen und mit Roadmap/SLAs umsetzen willst, lohnt sich Unterstützung durch eine spezialisierte Magento Agentur.


